UTF
Allgemein
UTF steht für UCS Transforamtion Format. Dabei steht UCS für Universial Coded Character Set. UTF ist die Kodierung der Zeichen, die ihrerseits mit einer Unicode-Nummer, durch die das Zeichen dann dargestellt wird. Damit ist UTF also die Kodierung der Unicode-Nummer.
ASCII
ASCII steht für American Standard Code for Information Interchange. Es handelt sich dabei um eine digitale Kodierung von Zeichen, die sieben Bits pro Zeichen verwendet. Damit können also 27 = 128 verschiedene Codes realisiert, womit 128 verschiedene Zeichen dargestellt werden können. Wegen dem begrenzten Platz und da ASCII von den westlichen Ländern definiert wurde, sind darin keine arabischen Schriftzeichen oder derartige Symbole definiert, sondern nur die lateinischen Buchstaben und noch einige oft verwendete Sonderzeichen. Viele Codes wurden auch dafür gebraucht, um Befehle zu definieren, wie zum Beispiel 'start of text' oder 'bell', womit eine Glocke geläutet werden kann, wenn ein digitaler Code hereinkommt. ASCII ordnet nun also jedem Zeichen eine Nummer zu, die einem 7 Bit langem Code entspricht. In der untenstehenden Grafik ist die ASCII-Tabelle mit einer Legende, in der die Steuerzeichen kurz beschrieben werden. Die Zeichennummer wird dabei mit einer Hexadezimalzahl angegeben, wobei die Zahl in der Tabelle über dem jeweiligen Zeichen steht.
ASCII Tabelle
[NUL] 01
[SOH] 02
[STX] 03
[ETX] 04
[EOT] 05
[ENQ] 06
[ACK] 07
[BEL] 08
[BS] 09
[HT] 0A
[LF] 0B
[VT] 0C
[FF] 0D
[CR] 0E
[SO] 0F
[SI] 1_ 10
[DLE] 11
[DC1] 12
[DC2] 13
[DC3] 14
[DC4] 15
[NAK] 16
[SYN] 17
[ETB] 18
[CAN] 19
[EM] 1A
[SUB] 1B
[ESC] 1C
[FS] 1D
[GS] 1E
[RS] 1F
[US] 2_ 20
[SP] 21
! 22
" 23
# 24
$ 25
% 26
& 27
' 28
( 29
) 2A
* 2B
+ 2C
, 2D
- 2E
. 2F
/ 3_ 30
0 31
1 32
2 33
3 34
4 35
5 36
6 37
7 38
8 39
9 3A
: 3B
; 3C
> 3D
= 3E
< 3F
? 4_ 40
@ 41
A 42
B 43
C 44
D 45
E 46
F 47
G 48
H 49
I 4A
J 4B
K 4C
L 4D
M 4E
N 4F
O 5_ 50
P 51
Q 52
R 53
S 54
T 55
U 56
V 57
W 58
X 59
Y 5A
Z 5B
[ 5C
\ 5D
] 5E
^ 5F
_ 6_ 60
` 61
a 62
b 63
c 64
d 65
e 66
f 67
g 68
h 69
i 6A
j 6B
k 6C
l 6D
m 6E
n 6F
o 7_ 70
p 71
q 72
r 73
s 74
t 75
u 76
v 77
w 78
x 79
y 7A
z 7B
{ 7C
| 7D
} 7E
~ 7F
[DEL]
Legende der Zeichen:
Steuerzeichen
NUL ≔ No operation = Füllzeichen, nichts
SOH ≔ Star of heading = Start der Überschrift
STX ≔ Start of text = Start des Textes
EOF ≔ End of file = Ende der Datei
ENQ ≔ Enquiry = Anfrage auf Antwort
ACK ≔ Acknowledgement = Bestätigung des Eingangs der Nachricht
BEL ≔ Bell = Glocke die geläutet wird
BS ≔ Backspace = Eine Position zurück
HT ≔ Horizontal tabulator = Abstand in horizintaler Richtung (meistens äquivalent zu 4 Leertasten)
LF ≔ Linefeed = Neue Zeile, bei neuen Computern mit der Enter-Taste
VT ≔ Vertical tabulator: Gleich wie HT in, einfach in vertikale Richtung
FF ≔ Form feed = Eine neue Seite wird angefangen
CR ≔ Carriage return = Zurück zum Anfang der Linie
SO ≔ Shift out = Bei Schreibmaschienen Schriftband nach verschieben (Farbwechsel auf rot)
SI ≔ Shift in = Bei Schreibmaschienen Schriftband nach verschieben (Farbwechsel auf schwarz)
DLE ≔ Data link escape = Folgende Objekte als Rohdaten interpretieren (nicht als Steuerzeichen oder ähnliches)
DC1, DC2, DC3, DC4 ≔ Device control = Gerätesteuerung 1, 2, 3, 4, zum Beispiel Übertragung unterbrechen
NAK ≔ Negative acknowledgement = Negative Bestätigung, im vorhergehenden Code wurde ein Fehler festgestellt
SYN ≔ Synchronous idle = Synchroner Leerlauf für synchrone Übertragungssysteme
ETB ≔ End of transmission block = Ende eines Überblocks
CAN ≔ Cancel = Stornieren, die vorhergehenden Daten sollen ignoriert werden
EM ≔ End of media = Ende des nutzbaren Teil des Bandes
SUB ≔ Substitute = Ersatz fehlerhafter Zeichen, wie strg-z
ESC ≔ Escape = Zeichen wird auf den meisten Systemen gesendet, also auch Flucht aus DLE
FS, GS, RS, US = Begrenzer von Felder von Datenstrukturen, hirarchische Ebene steigt ab in Reihenfolge
SP ≔ Space = Leerraum, Abstand
DEL ≔ Delete = Löschen des vorhergehenden Zeichens
Buchstaben vom lateinischen Alphabet
Ziffern vom Dezimalsystem
Satzzeichen, Klammern, Syntax
Beispiel Aufgaben
| Zeichen | ASCII (hexadezimal) | ASCII (binär) | ASCII (dezimal) |
|---|---|---|---|
ISO/IEC 8859
Zwar reichen die 95 druckbaren aus, damit man sich im modernen Englisch austauschen kann. Das Problem liegt aber darin, dass viele Sprachen, die ebenfalls auf dem lateinischen Alphabet basieren weitere Symbole für eine vernünftige Kommunikation benötigen. Mit dem Versuch dieses Problem zu beheben wurde ISO/IEC 8859 mit 96 weiteren Druckbaren Zeichen eingeführt. Dabei sind die ersten 128 Hexadezimalzahlen den gleichen Zeichen zugeordnet wie in der ASCII-Tabelle, damit diese kompatibel ist. Die Steuerungsbefehle wurden bei ISO/IEC 8859 weggelassen, da dieses System für Computer und nicht mehr für Schreibmaschinen konzipiert wurde, womit alle diese Befehle unnötig werden. Die insgesamt 95 + 96 = 191 Zeichen in ISO/IEC 8859-1 reichen aber nicht aus, um alle Sonderzeichen der häufig verwendeten Sprachen in den westlichen Ländern. Deswegen wurden 15 verschiedene ISO/IEC-Tabellen eingeführt, wobei bei allen die erste Hälfte genau gleich ist, damit sie alle mit der alten ASCII-Tabelle kompatibel sind. Die unten aufgeführte Tabelle ISO/IEC 8859-1 wird unter anderem von Geräten verwendet, die ihre Spracheinstellung auf Deutsch gestellt haben.
ISO/IEC 8859-1
8-Bit Kodierung, Variante Latin-1, für westeuropäische Länder
[SP] 21
! 22
" 23
# 24
$ 25
% 26
& 27
' 28
( 29
) 2A
* 2B
+ 2C
, 2D
- 2E
. 2F
/ 3_ 30
0 31
1 32
2 33
3 34
4 35
5 36
6 37
7 38
8 39
9 3A
: 3B
; 3C
> 3D
= 3E
< 3F
? 4_ 40
@ 41
A 42
B 43
C 44
D 45
E 46
F 47
G 48
H 49
I 4A
J 4B
K 4C
L 4D
M 4E
N 4F
O 5_ 50
P 51
Q 52
R 53
S 54
T 55
U 56
V 57
W 58
X 59
Y 5A
Z 5B
[ 5C
\ 5D
] 5E
^ 5F
_ 6_ 60
` 61
a 62
b 63
c 64
d 65
e 66
f 67
g 68
h 69
i 6A
j 6B
k 6C
l 6D
m 6E
n 6F
o 7_ 70
p 71
q 72
r 73
s 74
t 75
u 76
v 77
w 78
x 79
y 7A
z 7B
{ 7C
| 7D
} 7E
~ 8_ N i c h t b e l e g t 9_ N i c h t b e l e g t A_ A0
NBSP A1
¡ A2
¢ A3
£ A4
¤ A5
¥ A6
¦ A7
§ A8
¨ A9
© AA
ª AB
« AC
¬ AD
SHY AE
® AF
¯ B_ B0
° B1
± B2
² B3
³ B4
´ B5
µ B6
¶ B7
· B8
¸ B9
¹ BA
º BB
» BC
¼ BD
½ BE
¾ BF
¿ C_ C0
À C1
Á C2
 C3
à C4
Ä C5
Å C6
Æ C7
Ç C8
È C9
É CA
Ê CB
Ë CC
Ì CD
Í CE
Î CF
Ï D_ D0
Ð D1
Ñ D2
Ò D3
Ó D4
Ô D5
Õ D6
Ö D7
× D8
Ø D9
Ù DA
Ú DB
Û DC
Ü DD
Ý DE
Þ DF
ß E_ E0
à E1
á E2
â E3
ã E4
ä E5
å E6
æ E7
ç E8
è E9
é EA
ê EB
ë EC
ì ED
í EE
î EF
ï F_ F0
ð F1
ñ F2
ò F3
ó F4
ô F5
õ F6
ö F7
÷ F8
ø F9
ù FA
ú FB
û FC
ü FD
ý FE
þ FF
ÿ
Beispiel Aufgaben
| Zeichen | ISO/IEC 8859-1 (hexadezimal) | ISO/IEC 8859-1 (binär) | ISO/IEC 8859-1 (dezimal) |
|---|---|---|---|
Unicode
Unicode ist ein internationaler Standard, durch den für jedes sinnvolle Zeichen aller bekannten Schrift- und Zeichensysteme ein digitaler Code festgelegt wird. Es werden also auch Symbole festgelegt, wie beispielsweise die Emoji. Unicode ist also die Entzifferungstabelle, mit der aufgrund eines Codes ein Zeichen dargestellt werden kann. Der digitale Code besteht dabei aus einer Nummer. Unicode wird regelmässig aktualisiert und es werden neue Zeichen hinzugefügt. Seit Mai 2019 enthält Unicode 137'929 verschiedene Zeichen aus insgesamt 150 Schriftsystemen.
Bei früher verwendeten Systemen, die einen digitalen Code für Zeichen festgelegt haben, kam immer das Problem auf, dass der Platz nicht ausreichte, da neue Zeichen aufgenommen werden mussten. Damit Unicode nicht auch durch ein grösseres System ersetzt muss, werden die Zeichen in Unicode mit 32 Bits kodiert. Damit gibt es also 232 = 4'294'967'296 Möglichkeiten, wie ein solcher Code aussehen kann und somit können über vier Milliarden verschiedene Zeichen kodiert werden. Unicode hat also noch sehr grosse Reserven für neue Zeichen
Da eine 32 Bit grosse Binärzahl zu viel Platz braucht wir die Unicodenummer fast überall im Hexadezimalformat angegeben. Eine Unicodenummer sieht folgendermassen aus: U+270D. Man kann also am U+ am Anfang erkennen, dass es sich um eine Unicodenummer handelt, wenn man ein Zeichen mit dieser Nummer darunter sieht. Wie du vielleicht bereits bemerkt hast, beinhaltet die Nummer, die als Beispiel genommen wurde lediglich 16 Bit. Dies scheint aber nur so, weil in der Darstellung die ersten 16 Bit weggelassen wurden, da diese alle die Ziffer 0 haben. Abgespeichert wird die Nummer aber trotzdem im 32 Bit-Format, sofern sie nicht noch kodiert wird.
UTF-8
UTF-8 ist eine Kodierung der Unicodenummer. UTF-8 ist eine Art der Entropiekodierung, da häufig verwendete Zeichen mit weniger Bit kodiert werden als Zeichen, die nur selten verwendet werden. UTF-8 wird von sehr vielen Websites verwendet (die Zeichen auf dieser Webseite werden auch über UTF-8 abgebildet), über 90% weltweit. Bei UTF-8 wird die Unicodenummer in 8 Bit, also 1 Byte grosse Blöcke unterteilt. Dabei entsprechen die ersten sieben Bits der ASCII-Tabelle, wodurch UTF-8 mit ASCII kompatibel gemacht wurde. Die genaue Vorgehensweise der Kodierung wird in der folgenden Grafik erklärt.
| Unicode-Bereich | UTF-8 Kodierung | Erklärung |
|---|---|---|
| 00000000 bis 0000007F | 0xxxxxxx | Dieser Bereich der UTF-8-Kodierung entspricht genau dem Code aus der ASCII-Tabelle. Die 0 am Anfang ist festgelegt, die restlichen Bits, die hier mit x angezeigt werden, können frei gewählt werden. Ein Zeichen, das in der ASCII-Tabelle vorkommt braucht also 1 Byte an Speicherplatz. |
| 00000080 bis 000007FF | 110xxxxx 10xxxxxx |
Wenn Zeichen ausserhalb der ASCII-Tabelle kodiert werden beginnt das erste Byte mit einer 1 und nicht mit einer 0. Nach dieser 1 folgen so viele weitere 1 wie viele der nachfolgenden Bytes miteinander interpretiert werden sollen. Das Ende dieser Folge von 1 wir mit einer 0 markiert. Die nachfolgenden Bytes beginnen alle mit dem Indikator 10. Die Bits, bei denen ein x abgebildet ist stehen für die Bits des Unicode-Zeichenwertes. Dabei bilden sie von rechts nach links gelesen die Unicode-Zahl von rechts nach links geschrieben ab. Überflüssige Bits können also nur im ersten oder im zweiten Byte stehen. |
| 00000800 bis 0000FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
|
| 00010000 bis 001FFFFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
Beispiel Aufgaben
Schreibe für den binären Unicode immer die niederwertigen (hinteren) 16 Bits, ausser wenn die hochwertigen Bits werden gebraucht, um die Zahl darzustellen, schreibe so viele Bits wie benötigt werden. Schreibe bei UTF-8 zwischen jedem Byte ein Leerzeichen als Hilfe zur Übersichtlichkeit. Schreibe für das Dezimalformat einfach so viele Stellen, wie benötigt werden und für das Hexadezimalformat alle 8 Bytes.
| Unicode (dezimal) | Unicode (binär) | Unicode (hexadezimal) | UTF-8 |
|---|---|---|---|
Der Nachteil von UTF-8 wird erst bei der Kodierung ersichtlich. Während UTF-8 zwar viel weniger Daten, bei beispielsweise einer Übertragung benötigt, wie wenn die Unicode-Nummer mit ihren 32 Bit roh übertragen werden würde, sind bei der Unicode-Nummer alle Zeichen mit einer gleich langen Bitfolge kodiert, während bei UTF-8 unterschiedlich lange Bitfolgen auftauchen können, was einen höheren Rechenaufwand erfordert. Deswegen verwendet zum Beispiel Microsoft Windows UTF-16 als Kompromiss zwischen UTF-8 und UTF-32.
UTF-16
UTF-16 ist auch eine Kodierung der Unicode-Nummer, mit der ein Zeichen dargestellt werden kann. Eine UTF-16 Kodierung besteht dabei analog zu UTF-8 aus 16 Bit grossen Blöcken. Dabei benötigt jedes Zeichen einen oder zwei solche Blöcke. Ein Zeichen benötigt also eine Datenmenge von 16 oder 32 Bit. Der Unicode-Zeichenbereich wird in UTF-16 in verschiedene Ebenen (Planes) unterteilt. Diese Ebenen bieten jeweils Platz für 216 = 65536 Zeichen, da jedes Zeichen in so einer Ebene mit einem 16 Bit langen Code kodiert wird. UTF-16 ist aufgrund des längeren Codes für die Zeichen nicht mehr kompatibel mit der ASCII-Tabelle. Unicode hat aber noch riesige Reserven, da in Unicode nur 137'929 Zeichen und Symbole vorkommen. Diese Reserven sind auch in UTF-16 vorhanden, weswegen nur 6 der 17 Ebenen gebraucht werden. Hier werden die 6 Ebenen, die in Gebrauch sind und die Kodierung der Zeichen, die in den Ebenen liegen erklärt. UTF-16 wird beispielsweise von Microsoft Windows als Kompromiss zwischen UTF-8 und UTF-32 verwendet. Auch SMS verwendet UTF-16, sobald ein Zeichen ausserhalb der ASCII-Tabelle dargestellt werden muss. Wird ein Zeichen ausserhalb ASCII verwendet wird jedes Zeichen im SMS mit UTF-16 kodiert. Deswegen kann ein SMS, bei dem die Grösse auf 140 Bytes beschränkt ist, 160 Zeichen enthalten, wenn nur Zeichen aus der ASCII-Tabelle verwendet werden, aber lediglich noch 70 Zeichen, wenn ein Symbol ausserhalb der ASCII-Tabelle verwendet wird.
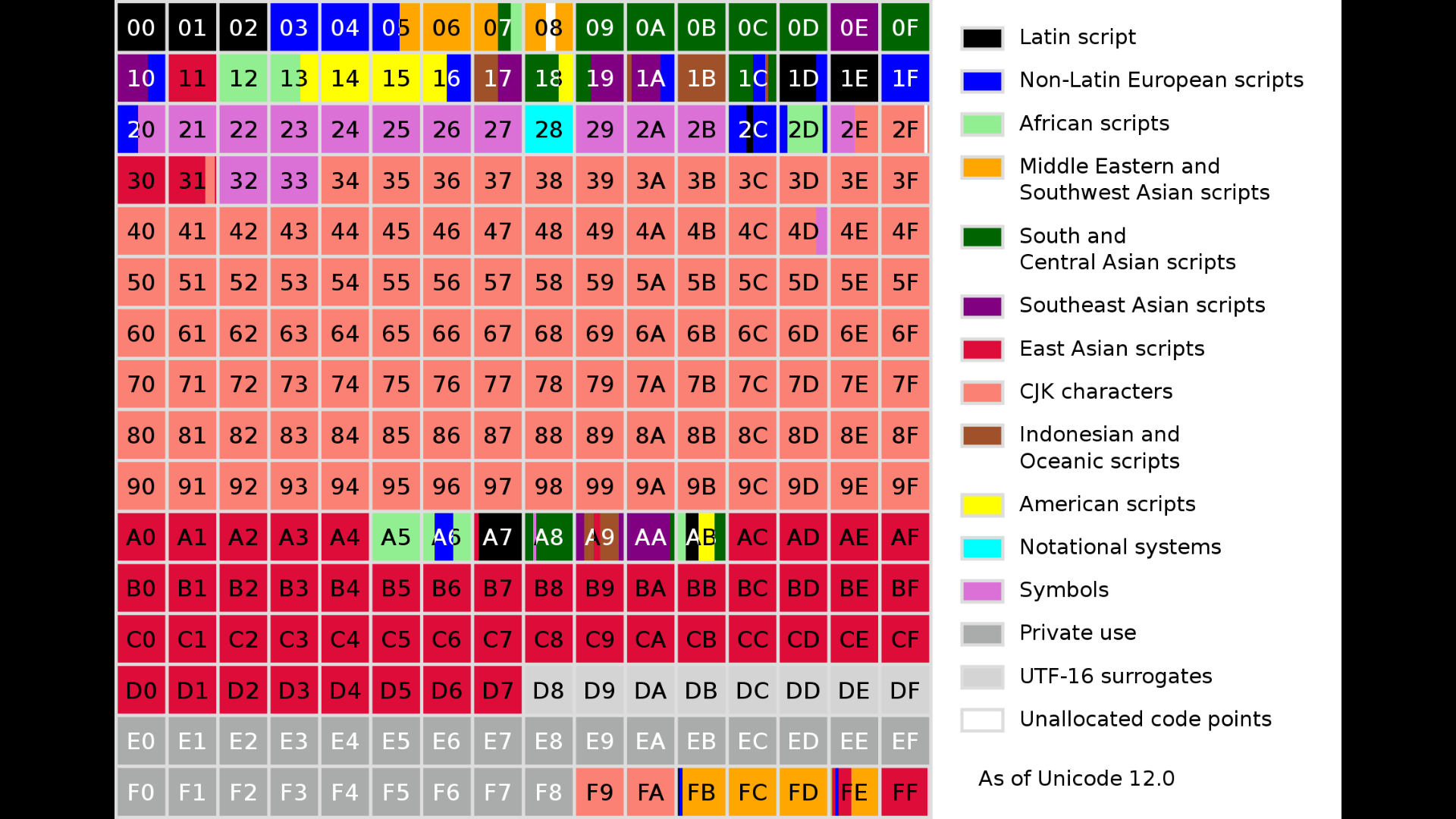
BMP - Basic Multilingual Plane - Plane 0
In der Ebene 0, der BMP sind die Unicodes von U+000016 bis U+FFFF16 = 010 bis 6553510 enthalten. Diese Zeichen sind die heute gebräuchlichen Schriftzeichen von fast allen modernen Sprachen (auch Symbolschriften, wie in Chinesisch oder Japanisch). Die sogenannten Surrogates, die noch vorkommen werden besetzt um den Wechsel in eine andere Ebene zu ermöglichen.
Die Unicode-Nummern der Zeichen aus der BMP bestehen aus 16 Nullen und 16 restlichen Bits. Deswegen können sie ganz einfach als 16 Bit Code kodiert werden. Von den 65535 möglichen Codes aus der BMP sind nur noch 64 Codes unbesetzt: von 087016 bis 089F16 = von 2'16010 bis 2'20710 und von 2FE016 bis 2FEF16 = von 12'25610 bis 12'27110. In der untenstehenden Grafik wird gezeigt, welche Bereiche Zeichen wo in der BMP liegen.
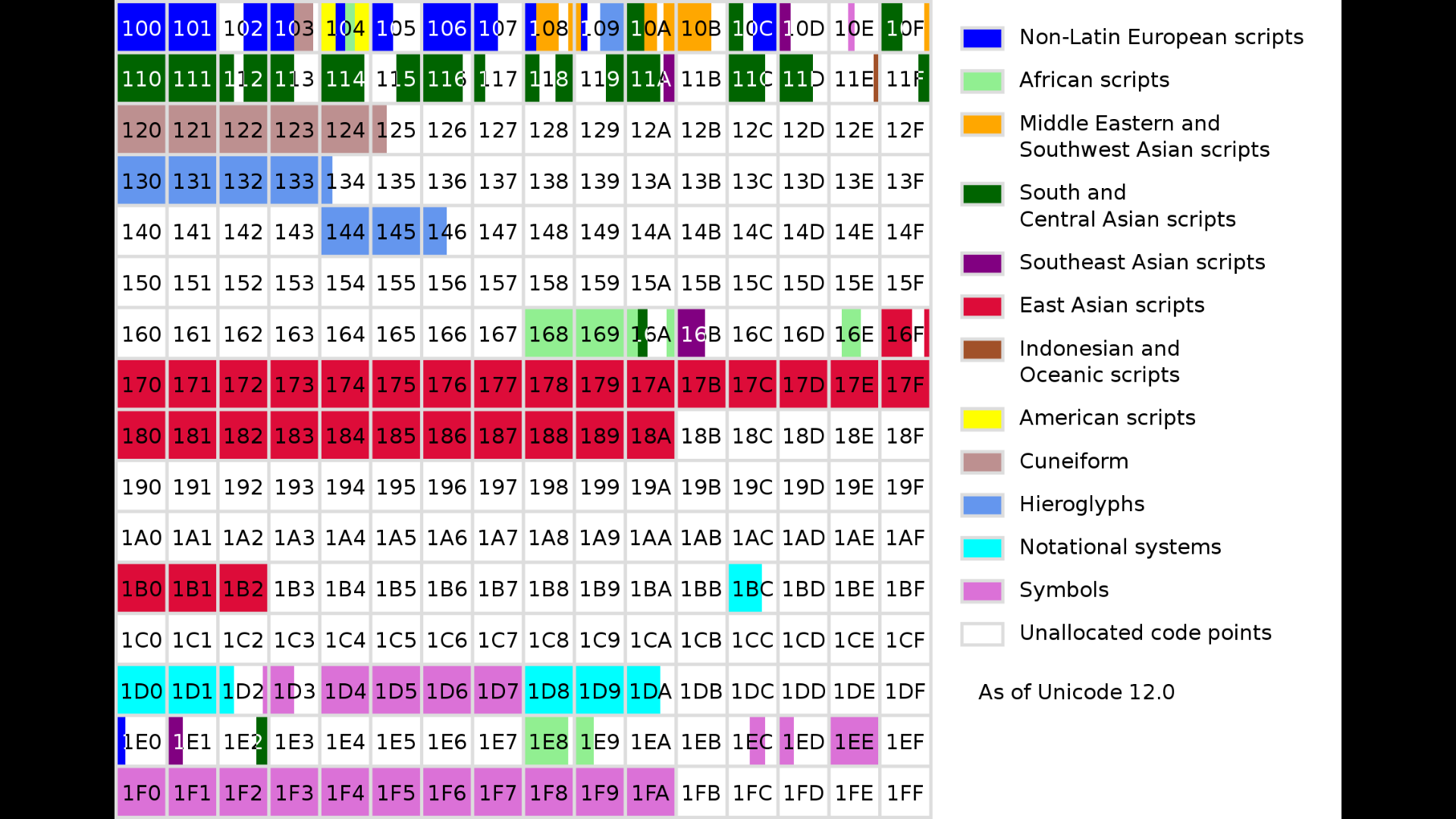
SMP - Supplementary Multilingual Plane - Plane 1
Die erste Ebene, die nicht in der BMP liegt ist die SMP, Supplementary Multilingual Plane. Diese Ebene enthält historische Schriftzeichen, aber auch Lautschriften oder Musiknoten. Zudem sind in dieser Ebene im Bereich der Symbole die Emoji enthalten. Die UTF-16 Kodierung der Zeichen, die ausserhalb der BNO liegt wird in der nachfolgenden Tabelle erklärt.
| Erklärung | Beispiel |
|---|---|
| Zuerst wird die Unicode-Nummer der darzustellenden Zeichens ins Binärformat umgewandelt | U+10101unicode = 1010116 = 0001 0000 0001 0000 0001 |
| Danach wird das höchstwertige Bit subtrahiert, was also einer subtraktion von 217 = 131'07210 entspricht. | -0001 0000 0000 0000 0000= 0000 0000 0001 0000 0001 |
| Nun wird die Binärzahl in der Mitte gespalten, wodurch zwei 10 Bit grosse Binärzahlen entstehen | 0000 0000 00 | 01 0000 0001 |
| Jetzt wird jeder 10-Bit Zahl ein Vorsatz angesetzt: der ersten 110110 und der zweiten 110111. | 1101 1000 0000 0000 1101 1101 0000 0001 |
| Die erhaltene Binärzahl wird noch ins Hexadezimalsystem übertragen und wir erhalten das Ergebnis der Kodierung | D800 DE01 |
In der untenstehenden Grafik wird angezeigt, wo sich welche Zeichen befinden.
SIP - Supplemantary Ideographic Plane - Plane 2
Die zweite Ebene ausserhalb der BMP ist die SIP, die Supplementary Ideographic Plane. Diese Ebene wird dazu verwendet, um japanische, chinesische, koreanische und vietnamesische Zeichen darzustellen. Daran, dass diese Zeichen selbst schon eine Zusatzebene brauchen, kann man erkennen, wieso sie nicht in der BMP stehen. Da sie ausserhalb der BMP stehen lohnt sich die UTF-16 Kodierung nicht mehr, sie ist sogar schlechter als UTF-32, da sie mehr Rechenaufwand verursacht, aber dennoch gleich viel Daten verbraucht. In der untenstehenden Grafik ist die SIP genauer aufgeführt.
 Drmccreedy, Roadmap to Unicode SIP, CC BY-SA 4.0
Drmccreedy, Roadmap to Unicode SIP, CC BY-SA 4.0
{kind=link}
SSP - Supplementary Special-purpose Plane - Plane 14
Die dritte Ebene ausserhalb der BMP ist die SSP, die Supplementary Special-purpose Plane. Diese Ebene wurde extra von den anderen Ebenen abgegrenzt, damit Zeichen, die zum Beispiel in der SMP kein Platz mehr haben nicht in diese Ebene gelegt werden. In dieser Ebene werden nicht grafische Zeichen, wie Kontrollzeichen zur Sprachmarkierung abgespeichert. Die Zeichen haben, wie man auch in der folgenden Grafik erkennen kann, nicht ihre eigene Ebene erhalten, da sie in der BMP keinen Platz gefunden haben, sondern da sie sich von den anderen Zeichen abgrenzen sollte.
 Drmccreedy, Roadmap to Unicode SSP, CC BY-SA 4.0
Drmccreedy, Roadmap to Unicode SSP, CC BY-SA 4.0
{kind=link}
PUA-A und PUA-B - Private Use Planes A/B - Planes 15/16
Die letzten zwei Ebenen sind in UTF-16 als die sogenannten Private Use Planes definiert. Diese Ebenen werden dazu gebraucht, um Zeichen ausserhalb des Unicodes zu definieren. Diese Zeichen werden von Schriftarten verwendet, um Hilfsglyphen zu verweisen, wie zum Beispiel Ligaturen (ineinander geschriebene Buchstaben, wie etwa æ). Solche Zeichen sind nur eingeschränkt interoperabel, können also nicht überall verwendet werden. Wenn eine Software Unicode unterstützt heisst es nicht, dass sie auch die Zuweisung von Zeichen durch andere Parteien wie die PUA-A/B unterstützt. Diese Hilfsglyphen aus diesen zwei Ebenen sind also nicht definiert in Unicode. Sie werden gebraucht, um beispielweise Firmenlogos darzustellen.
Beispiel Aufgaben
Schreibe für den binären Unicode immer die niederwertigen (hinteren) 16 Bits, ausser wenn die hochwertigen Bits werden gebraucht, um die Zahl darzustellen, schreibe so viele Bits wie benötigt werden. Schreibe für das Dezimalformat einfach so viele Stellen, wie benötigt werden und für das Hexadezimalformat alle 8 Ziffern.
| Unicode (dezimal) | Unicode (binär) | Unicode (hexadezimal) | UTF-16 (hexadezimal) |
|---|---|---|---|
UTF-32
UTF-32 ist die simpelste Kodierung der Unicode-Nummer. Dabei wird einfach die Unicode-Nummer mit einer 32 Bit grossen Zahl dargestellt. Damit verbraucht ein Zeichen in UTF-32 immer 32 Bit = 4 Byte Daten, obwohl Zeichen aus der ASCII-Tabelle mit UTF-8 mit lediglich 8 Bit = 1 Byte dargestellt werden können. Der Vorteil von UTF-32 ist, dass der Rechenaufwand bei der Darstellung nur so viel ist, wie für das Dekodieren der Unicode-Nummer gebraucht wird. Bei UTF-8 und UTF-16 hingegen muss zuerst die Unicode-Nummer identifiziert werden.